微服务学习 - FaaS框架(平台)的函数处理方式
概述
本文对比了几种主流的FaaS(Serverless)框架(平台)中的从事件到函数的工作方式,同时根据对比分析的结果,探讨FaaS(Serverless)框架(平台)在处理事件源调用与函数内容处理方面的设计优化。
函数框架中,函数的工作方式主要分为以下几个部分:
- 函数的触发器、输入和输出
- 函数服务的监听地址、监听协议、监听端口
- 框架内函数的编写规范
以下将根据上述三点内容对比Azure Function、AWS Lambda、Google Cloud Functions、Fission、OpenWhisk、Kubeless这几种框架(平台)的实现方式。
Azure Function
Azure Function需要先定义一个Function与Bindings的配置,内容包含了Function的路径,关联的Trigger、Bindings Input和Output。
在函数中使用Bindings的in类型的name作为参数,out类型可以直接取$return的值。
example
function.json:
1 | { |
__init__.py:
1 | import azure.functions as func |
AWS Lambda
AWS Lambda通过定义event-source-mapping,即事件与Function的关联关系,来实现函数与事件、数据源的交互。
在用户函数中使用SDK方式获取函数的相关信息。或者将事件对象和上下文对象传递给函数。
example
1 | def lambda_handler(event, context): |
Fission
Fission通过创建Trigger资源来定义事件和Function的关联关系,之后使用Router完成Function的触发。
在用户函数中,以通用的HTTP Request处理方式来处理请求。
支持HTTP和MQ以及MQ+KEDA的触发方式。

example
1 | package main |
OpenWhisk
OpenWhisk使用Rule资源来关联Trigger和Actions。主要使用HTTP请求,Controller接受到请求后发送给Kafka,同步返回后由Kafka以异步的方式发布给所有Invoker。
在Actions中使用一个map对象来传入参数。参数使用--param方式传递给Actions。
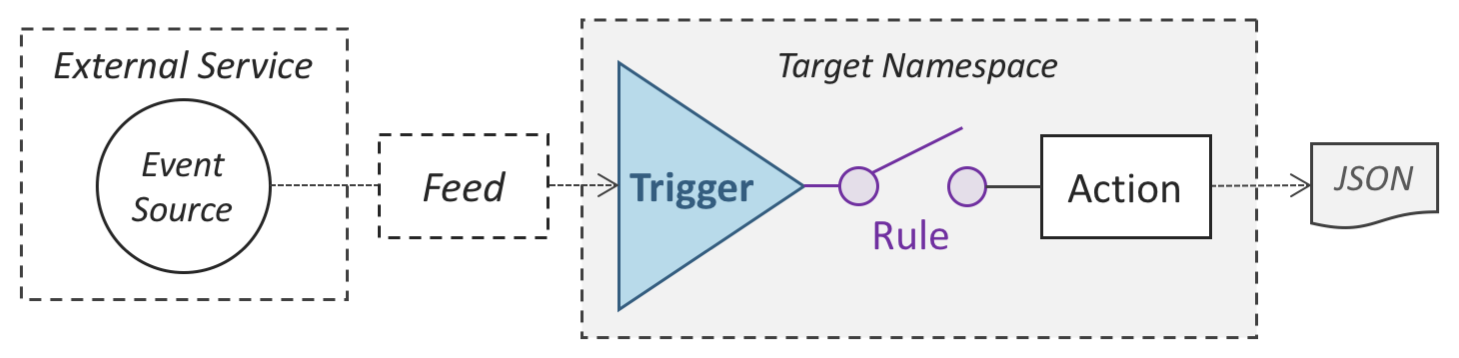
example
1 | package main |
OpenFaaS
OpenFaaS提供了OpenFaaS Gateway作为函数请求的入口。主要通过HTTP方式调用函数;针对非HTTP trigger,使用特定的connector作为关联。
同时提供了faas-provider为函数提供CRUD api。
配合函数的配置,用于关联Gateway和Function。
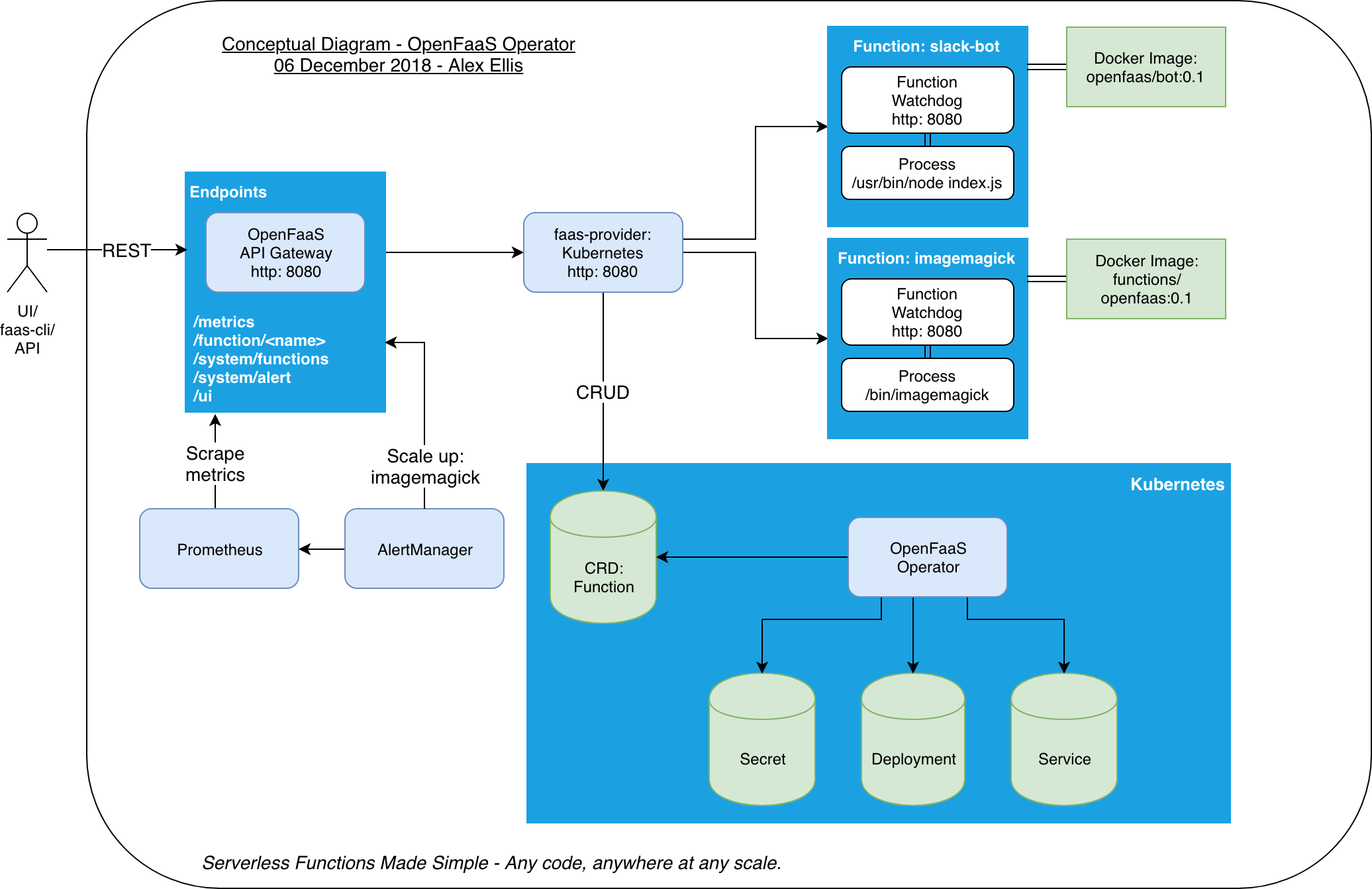
example
hello-python.yaml:
1 | provider: |
hello-python/handler.py:
1 | import requests |
Kubeless
Kubeless通过定义Trigger和Function的关联关系,来实现Function与事件、数据源的交互。
Function中使用SDK的方式来处理数据。
example
1 | package kubeless |
Google Cloud Functions
GCP主要支持HTTP、Cloudevent、后台事件三种类型的函数。
在用户函数中,为了适配不同的事件源数据结构,需要根据数据源的规则编写特定的数据结构来处理请求内容。
example
1 |
|
总结
函数参数
以上框架中,对函数入参的处理可以分为由框架封装和不封装(或自定义)两种类型。GCP、Fission选择让使用者自行处理函数请求,如函数调用大部分情况下为HTTP请求方式,那么就使用类似func Handler(w http.ResponseWriter, r *http.Request)的形式来处理HTTP请求。另一些框架如Kubeless、OpenFaaS、AWS Lambda等则对函数入参进行了封装,意图在于抽象输入数据的处理方式,即无论请求为什么格式,都使用框架提供的SDK处理库来获取数据。
不封装(或自定义)入参
- 优点
- 学习成本低
- 便于移植
- 缺点
- 针对不同的请求方法变更函数入参
- 扩展性差
- 优点
封装入参
- 优点
- 扩展性高,可以适配多种数据源
- 缺点
- 学习成本高,需要使用者针对不同数据源编写不同的定义
- 优点
从以上框架的案例中看,封装入参的方式可以使函数在同一个框架内具有很高的灵活性和可扩展性。例如在函数的数据输入源变更后,函数本身不需要再做对应的入参适配,从而降低了使用者的开发成本。
这种类型的框架往往需要使用一个函数外的配置,用于定义函数和触发器、数据源、数据目标之间的关联关系。而且这种框架通常可以适配更多的数据源。从这个角度看封装入参方式比不封装(或自定义)入参方式具备更大的潜力。
事件关联
事件驱动是Serverless的精髓所在,如何合理高效地关联事件源(或触发器)与函数,是一个FaaS框架需要着重考虑的地方。
首先需要明确几个概念:
事件源(Event Source),表示事件的来源,如Kafka服务、对象存储服务
事件(Event),事件源的一种行为实例,如向Kafka服务器发送了一条消息、向对象存储服务中上传了一个文件
触发器(Trigger),对事件目的的一种抽象,如当收到消息时需要做什么
可以看出以上几种主流的框架(平台)中均使用了函数外配置定义的方式,声明了事件源与函数的关联关系。这部分暂时并没有出现较大的设计分歧。
Azure Function中的函数配置function.json。
1 | { |
Fission中的HTTP Trigger:
1 | fission httptrigger create --url /hello --method GET --function hello |
配置内容
无论哪种关联方案,在配置定义中通常需要具备以下内容:
- 使用者通用元数据,如用户ID、RequestID等其他上下文信息
- 事件源的定义,如名称、类型、服务地址、数据类型
- 触发器的定义,如名称、类型、触发规则、触发周期、执行方式
- 函数的定义,如名称、监听地址
- 提供自定义的key-value参数,如环境变量,以及用于适配不同的Runtime
事件的处理
在事件的处理上,可以参考Argo Events的架构设计。
在Argo Events中,事件源中事件的格式被统一为CloudEvents类型,通过EventBus传输,再由Sensor接受,根据其中的Triggers规则来分发给具体的执行者。
事件总线的加入即对事件有一个聚合处理,又可以统一事件的数据类型和传输流程。针对一些小规模的场景,也可以提供简化版的模式(仅保留Triggers),作为一种轻量级的解决方案。
框架工具库
GCP提供了一套functions-framework,用于提供一个统一的main函数模板。用户函数将以package的方式嵌入main函数。
这样一来就可以在main函数与用户函数之间开辟一块空间,在其中集成各种用于完善函数计算生态的工具,如数据转换、日志收集、异常处理等等。
Functions-framework + SDK
Functions Frameworks aim to minimize the amount of boilerplate and configuration required to create a runnable stateless container. The overall goal is to maximize productivity and free the developer from repetitive development tasks that do not directly contribute to solving customer problems.
这部分的原理比较简单。但是为了实现上面所说的封装用户函数参数、根据配置关联函数与事件源,那么就不能仅仅渲染一个main函数模板。
我们预想在处理输入数据时,需要将它们转换为统一的格式(遵照配置定义),如将HTTP请求Body、Kafka中的消息,统统转换为byte类型的数据后再传递给用户函数。(当有了事件框架后,可以利用事件框架将事件内容统一转换为CloudEvents格式的消息)
对应的,在处理输出数据时,需要将它们由统一的格式转换为符合输出目标类型的数据(遵照配置定义),如用户函数仅需返回byte类型的数据,之后由Functions-framework将它组合成特定的数据结构。
可以看出Functions-framework的工作仍然局限于用户函数之外,所以还一个可以工作于用户函数内部的工具。可以理解为这部分即是SDK,其作用是提供函数在框架中的上下文信息(如关联的事件源信息、平台中的用户信息甚至服务器级别信息等)给用户函数,并让使用者在用户函数内具备处理这些信息的能力。
结合Functions-framework,举例说明:
以python语言为例
假设根据框架的函数编写规范,用户函数仅需要一个入参context:
1 | def my_func(context): |
当用户需要从一个名为”Kafka-trigger”的事件源获取消息时,他可以这么写:
1 | data = context.in["Kafka-trigger"].get_data() |
当用户需要将数据发送给一个名为”HTTP-output”的Bindings Output对象时,他可以这么写:
1 | data = "Hello World!" |
这样一来就免去了用户适配各种数据源、中间件的过程,同时也让代码的语义更加明确。
Dapr
框架工具库这部分的设计并不复杂,实现的难点在于如何制定一套语义明确、功能强大的SDK工具。而从另一个角度看,框架工具看的作用可以理解为:
- 封装用户函数为一个标准的调用地址提供给数据输入源
- 封装数据输出目标为一个标准的调用地址提供给用户函数
这和Dapr的工作原理几乎一致。不仅如此,Dapr还提供了对接多种数据类型的方式:Bindings、Pub/Sub、Service Invoke等。

在Kubernetes中,Dapr以Sidecar的方式实现了Functions-framework的功能。是否能用Dapr直接作为FaaS(Serverless)框架(平台)中的框架工具库?
我认为是可行的,但还需要根据框架的最终目标做一些改造。