OpenFunction - 以 Serverless 的方式实现 Kubernetes 日志告警
概述
当我们将容器的日志收集到消息服务器之后,我们该如何处理这些日志?部署一个专用的日志处理工作负载可能会耗费多余的成本,而当日志体量骤增、骤降时亦难以评估日志处理工作负载的待机数量。本文提供了一种基于 Serverless 的日志处理思路,可以在降低该任务链路成本的同时提高其灵活性。
我们的大体设计是使用 Kafka 服务器作为日志的接收器,之后以输入 Kafka 服务器的日志作为事件,驱动 Serverless 工作负载对日志进行处理。据此的大致步骤为:
- 搭建 Kafka 服务器作为 Kubernetes 集群的日志接收器
- 部署 OpenFunction 为日志处理工作负载提供 Serverless 能力
- 编写日志处理函数,抓取特定的日志生成告警消息
- 配置 Notification Manager 将告警发送至 Slack
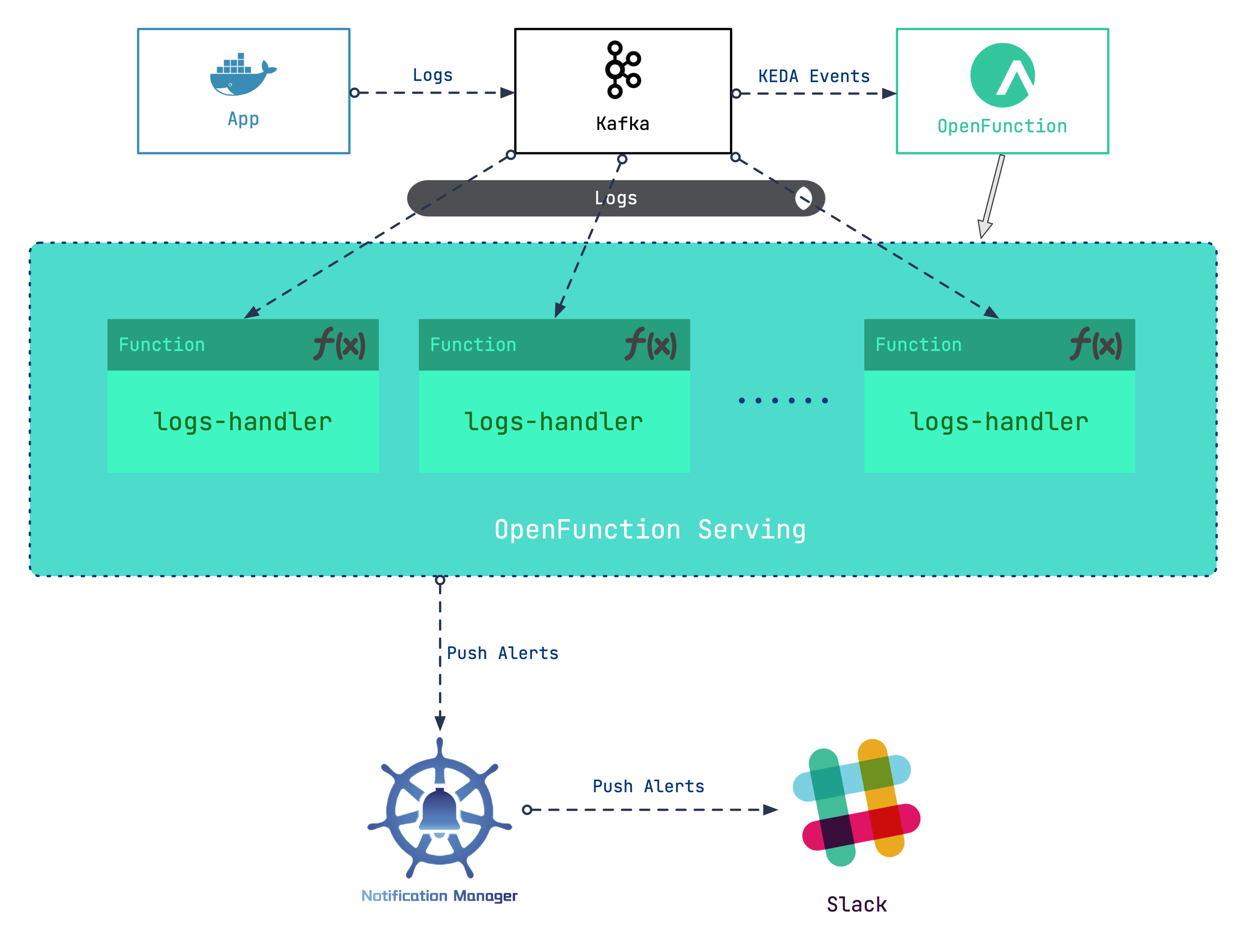
在这个场景中,我们会利用到 OpenFunction 带来的 Serverless 能力。
OpenFunction 是 KubeSphere 社区开源的一个 FaaS(Serverless)项目,旨在让用户专注于他们的业务逻辑,而不必关心底层运行环境和基础设施。该项目当前具备以下关键能力:
- 支持通过 dockerfile 或 buildpacks 方式构建 OCI 镜像
- 支持使用 Knative Serving 或 OpenFunctionAsync ( KEDA + Dapr ) 作为 runtime 运行 Serverless 工作负载
- 自带事件驱动框架
使用 Kafka 作为日志接收器
首先,我们为 KubeSphere 平台开启 logging 组件(可以参考 启用可插拔组件 获取更多信息)。然后我们使用 strimzi-kafka-operator 搭建一个最小化的 Kafka 服务器。
在 default 命名空间中安装 strimzi-kafka-operator :
1
2helm repo add strimzi https://strimzi.io/charts/
helm install kafka-operator -n default strimzi/strimzi-kafka-operator运行以下命令在 default 命名空间中创建 Kafka 集群和 Kafka Topic,该命令所创建的 Kafka 和 Zookeeper 集群的存储类型为 ephemeral,使用 emptyDir 进行演示。
注意,我们此时创建了一个名为 “logs” 的 topic,后续会用到它
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49cat <<EOF | kubectl apply -f -
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: kafka-logs-receiver
namespace: default
spec:
kafka:
version: 2.8.0
replicas: 1
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
log.message.format.version: '2.8'
inter.broker.protocol.version: "2.8"
storage:
type: ephemeral
zookeeper:
replicas: 1
storage:
type: ephemeral
entityOperator:
topicOperator: {}
userOperator: {}
---
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: logs
namespace: default
labels:
strimzi.io/cluster: kafka-logs-receiver
spec:
partitions: 10
replicas: 1
config:
retention.ms: 7200000
segment.bytes: 1073741824
EOF运行以下命令查看 Pod 状态,并等待 Kafka 和 Zookeeper 运行并启动。
1
2
3
4
5
6kubectl get po
NAME READY STATUS RESTARTS AGE
kafka-logs-receiver-entity-operator-568957ff84-nmtlw 3/3 Running 0 8m42s
kafka-logs-receiver-kafka-0 1/1 Running 0 9m13s
kafka-logs-receiver-zookeeper-0 1/1 Running 0 9m46s
strimzi-cluster-operator-687fdd6f77-cwmgm 1/1 Running 0 11m运行以下命令查看 Kafka 集群的元数据:
1
2
3
4启动一个工具 pod
kubectl run utils --image=arunvelsriram/utils -i --tty --rm
查看 Kafka 集群的元数据
kafkacat -L -b kafka-logs-receiver-kafka-brokers:9092
我们将这个 Kafka 服务器添加为日志接收器。
以 admin 身份登录 KubeSphere 的 Web 控制台。点击左上角的平台管理,然后选择集群管理。
如果您启用了多集群功能,您可以选择一个集群。
在集群管理页面,选择集群设置下的日志收集。
点击添加日志接收器并选择 Kafka。输入 Kafka 代理地址和端口信息,然后点击确定继续。

运行以下命令验证 Kafka 集群是否能从 Fluent Bit 接收日志:
1
2
3
4启动一个工具 pod
kubectl run utils --image=arunvelsriram/utils -i --tty --rm
检查 logs topic 中的日志情况
kafkacat -C -b kafka-logs-receiver-kafka-0.kafka-logs-receiver-kafka-brokers.default.svc:9092 -t logs
部署 OpenFunction
按照概述中的设计,我们需要先部署 OpenFunction。OpenFunction 项目引用了很多第三方的项目,如 Knative、Tekton、ShipWright、Dapr、KEDA 等,手动安装较为繁琐,推荐使用 Prerequisites 文档 中的方法,一键部署 OpenFunction 的依赖组件。
其中
--with-shipwright表示部署 shipwright 作为函数的构建驱动--with-openFuncAsync表示部署 OpenFuncAsync Runtime 作为函数的负载驱动
而当你的网络在访问 Github 及 Google 受限时,可以加上--poor-network参数用于下载相关的组件
1 | sh hack/deploy.sh --with-shipwright --with-openFuncAsync --poor-network |
部署 OpenFunction:
此处选择安装最新的稳定版本,你也可以使用开发版本,参考 Install 文档
为了可以正常使用 ShipWright ,我们提供了默认的构建策略,可以使用以下命令设置该策略:
1 | kubectl apply -f https://github.com/OpenFunction/OpenFunction/releases/download/v0.3.0/bundle.yaml |
编写日志处理函数
我们以 创建并部署 WordPress 为例,搭建一个 WordPress 应用作为日志的生产者。该应用的工作负载所在的命名空间为 “demo-project”,Pod 名称为 “wordpress-v1-f54f697c5-hdn2z”。
当请求结果为 404 时,我们收到的日志内容如下:
1 | {"@timestamp":1629856477.226758,"log":"*.*.*.* - - [25/Aug/2021:01:54:36 +0000] \"GET /notfound HTTP/1.1\" 404 49923 \"-\" \"curl/7.58.0\"\n","time":"2021-08-25T01:54:37.226757612Z","kubernetes":{"pod_name":"wordpress-v1-f54f697c5-hdn2z","namespace_name":"demo-project","container_name":"container-nrdsp1","docker_id":"bb7b48e2883be0c05b22c04b1d1573729dd06223ae0b1676e33a4fac655958a5","container_image":"wordpress:4.8-apache"}} |
我们的需求是:当一个请求结果为 404 时,发送一个告警通知给接收器(可以根据 配置 Slack 通知 配置一个 Slack 告警接收器),并记录命名空间、Pod 名称、请求路径、请求方法等信息。按照这个需求,我们编写一个简单的处理函数:
你可以从 OpenFunction Context Spec 处了解 openfunction-context 的使用方法,这是 OpenFunction 提供给用户编写函数的工具库
你可以通过 OpenFunction Samples 了解更多的 OpenFunction 函数案例
1 | package logshandler |
我们将这个函数上传到代码仓库中,记录代码仓库的地址以及代码在仓库中的目录路径,在下面的创建函数步骤中我们将使用到这两个值。
你可以在 OpenFunction Samples 中找到这个案例。
创建函数
接下来我们将使用 OpenFunction 构建上述的函数。首先设置一个用于访问镜像仓库的秘钥文件 push-secret(在使用代码构建出 OCI 镜像后,OpenFunction 会将该镜像上传到用户的镜像仓库中,用于后续的负载启动):
1 | REGISTRY_SERVER=https://index.docker.io/v1/ REGISTRY_USER=<your username> REGISTRY_PASSWORD=<your password> |
应用函数 logs-handler-function.yaml:
函数定义中包含了对两个关键组件的使用:
Dapr 对应用程序屏蔽了复杂的中间件,使得 logs-handler 可以非常容易地处理 Kafka 中的事件
KEDA 通过监控消息服务器中的事件流量来驱动 logs-handler 函数的启动,并且根据 Kafka 中消息的消费延时动态扩展 logs-handler 实例
1 | apiVersion: core.openfunction.io/v1alpha1 |
结果演示
我们先关闭 Kafka 日志接收器:在日志收集页面,点击进入 Kafka 日志接收器详情页面,然后点击更多操作并选择更改状态,将其设置为关闭。
停用后一段时间,我们可以观察到 logs-handler 函数实例已经收缩到 0 了。
再将 Kafka 日志接收器激活,logs-handler 随之启动。
1 | kubectl get po --watch |
接着我们向 WordPress 应用一个不存在的路径发起请求:
1 | curl http://<wp-svc-address>/notfound |
可以看到 Slack 中已经收到了这条消息(与之对比的是,当我们正常访问该 WordPress 站点时, Slack 中并不会收到告警消息):

进一步探索
同步函数的解决方案
为了可以正常使用 Knative Serving ,我们需要设置其网关的负载均衡器地址。(你可以使用本机地址作为 workaround)
将下面的 “1.2.3.4” 替换为实际场景中的地址。
1
2
3
4
5kubectl patch svc -n kourier-system kourier \
-p '{"spec": {"type": "LoadBalancer", "externalIPs": ["1.2.3.4"]}}'
kubectl patch configmap/config-domain -n knative-serving \
--type merge --patch '{"data":{"1.2.3.4.sslip.io":""}}'除了直接由 Kafka 服务器驱动函数运作(异步方式),OpenFunction 还支持使用自带的事件框架对接 Kafka 服务器,之后以 Sink 的方式驱动 Knative 函数运作。可以参考 OpenFunction Samples 中的案例。
在该方案中,同步函数的处理速度较之异步函数有所降低,当然我们同样可以借助 KEDA 来触发 Knative Serving 的 concurrency 机制,但总体而言缺乏异步函数的便捷性。(后续的阶段中我们会优化 OpenFunction 的事件框架来解决同步函数这方面的缺陷)
由此可见,不同类型的 Serverless 函数有其擅长的任务场景,如一个有序的控制流函数就需要由同步函数而非异步函数来处理。
综述
Serverless 带来了我们所期望的对业务场景快速拆解重构的能力。
如本案例所示,OpenFunction 不但以 Serverless 的方式提升了日志处理、告警通知链路的灵活度,还通过函数框架将通常对接 Kafka 时复杂的配置步骤简化为语义明确的代码逻辑。同时,我们也在不断演进 OpenFunction,将在之后版本中实现由自身的 Serverless 能力驱动自身的组件运作。